Last Friday I presented a session on outcome based metrics at the Lean Agile Network meetup in Toronto. Based on the popularity of the session and the questions which we didn’t have the time to address, the topic is clearly on many people’s mind. More to come on metrics in future posts, but for now we’ll focus on what you can learn from the simplest metric of them all: throughput.
“ the amount of something that passes through something.”
In an attempt to make this online definition more concrete and useful to measure software delivery performance, I suggest using:
“the features that a team can deliver per week.”
We measure throughput because we want to answer the most common question in software engineering: how much functionality will the team be able to deliver by our deadline? Or a slight variation thereof:
“When will we be done?”
But our definition raises some additional questions:
What does deliver mean? To production? To the test environment?
What does feature mean? A task? As story? A bug?
Why use a week instead of an iteration or a sprint?
Below I’ll discuss how creating a strict definition of throughput provides us with insights that we otherwise might never get.
Holistic
Ultimately, the goal of every software delivery team is to put the results of its hard work in the hands of the end users. Therefor, the best way to measure throughput is to take a holistic approach and measure how many features end up in production.
However, many organizations are prevented by legacy policies and delivery practices to regularly publish new functionality to production. As delivery is maturing, it makes more sense to also measure throughput of the system that the delivery team has control over. While we learn about the organization’s ability to deliver value to its customers from measuring throughput of the value stream all the way to production, we can learn from the team’s productivity by measuring the truncated value stream.
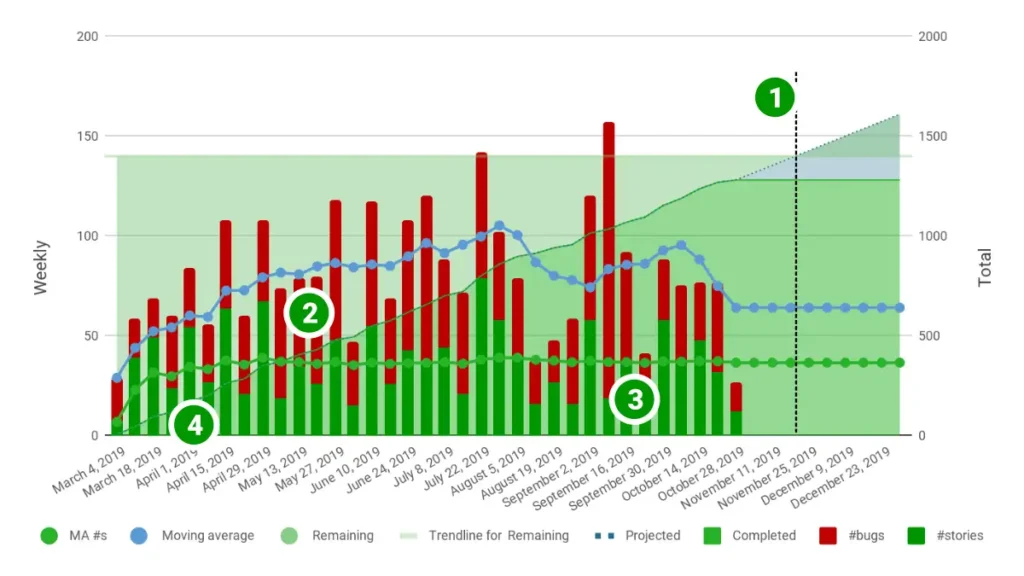
The graph below shows the throughput over time of a software delivery team of about 40 people strong. Every week, the tested functionality is deployed to production. However, driven by the desire of management to better understand the team’s productivity, the graph shows when the team considers the stories done.
Value delivery
I have experimented with measuring throughput in a variety of ways and always came to the same conclusion, best summarized as the 7th principle of the Agile Manifesto:
“working software is the primary measure of progress.”
Measuring throughput means measuring the number of distinct pieces of user functionality delivered. If your team works with real user stories (as opposed to packets of work that the team calls user stories, but don’t deliver any user value), then the amount of user stories that are delivered on a weekly basis is your measuring stick. If you are a translation agency, it might be the number of translated pages. Regardless of what value your team delivers, throughput needs to measure this value.
The green bars in the graph represent the number of stories delivered every week. The green area on the right hand side of the diagonal slope is the cumulative value delivered over time, usually called the burn-up chart. The end tail of the slope is a straight line, projecting the future throughput based on the moving average of the six most recent values. The green area on the left hand side of the diagonal represents the remaining scope that the team is expected to deliver. You can clearly see that at the current pace, the team will have delivered all approximately 1400 stories by the second half of November as indicated by number 1.
So what about defects?
Granted, I usually also measure how many defects the team can fix in a week’s time. However, lumping those in with the functionality hides the fact that the team spends valuable time to fix quality concerns.
We mentioned earlier that it is important to look at the software delivery process holistically to measure what really matters. It is for the same reason that we cannot be blinded by how efficient the team is at fixing defects. Team productivity is a function of the software delivery process, the team’s skills and the software that is being extended. The quality of the underlying code will have an impact on the actual productivity of the team. It’s unclear what we would measure if we include the fixing of defects in our throughput metric:
if the team paid little attention to quality, we can expect it to deliver functionality faster which would result in a high throughput;
the following weeks, the team would have to deal with the defects it introduced, also resulting in high throughput.
Clearly the above situation paints a skewed reality and does not provide insights into the value the team is actually capable of delivering. In the graph, this is visible at number 2, where the total throughput (the blue line) suggests that the team’s output is increasing, while the actual throughput (the green line) is stable or even regresses.
What about our estimates?
Yes, in only counting how many features the team can deliver, we ignore the estimated effort to complete those features. While this is not recorded in the graph, I have experimented with many teams by measuring both what is usually called velocity (the amount of story points delivered per week or sprint) and throughput as described above. Time and time again, velocity kept on increasing over time and turned out to be a less accurate representation of the real outcome than throughput was. Most teams stopped calculating velocity altogether and only used the estimation process to draw out differences in understanding what work was involved when delivering the functionality.
Number 3 shows that the team’s delivery of stories is fairly stable over time. The velocity for this same team oscillated significantly around an ever increasing trend line.
Measuring weekly
I find it valuable to disconnect the period over which to measure throughput from the iteration length the team uses. This makes the metric just as applicable for teams that use flow-based delivery like Kanban and do not rely on fixed length iterations. Additionally, it surfaces patterns that might exist within a multi-week iteration.
Number 4 in the graph shows that this team’s throughput behaves according to a two week cycle in which the second week produces many more delivered features than the first week does. The team is in fact delivering according to a two week sprint cycle, and seems to not spread out the work evenly during the sprint. Other metrics show that the team is starting to work on almost all functionality early and completes most features only by the very end of the sprint, but that is a topic for another blog post.
If we look a little bit deeper, we can even see that when the team delivers vastly more functionality one week, it usually results in more bug fixes the week after. This information will support teams in their aim to deliver with higher quality.
Why not calculate daily throughput then?
If your teams deliver multiple features a day, by all means measure throughput daily. Most teams I have worked with have not reached that level of maturity where stories are that small, that most of them can be delivered in a day.
Conclusion
I hope it is clear by now that there is an awful lot to learn from measuring throughput. Since it takes very little overhead to measure, it is often the first metric that I introduce with a new team as it makes many common team challenges visible.
We will touch on a couple of other metrics in future posts, but let us know on our LinkedIn page if you find this valuable in the mean time.
Successful organizations rely on meaningful metrics to navigate complex initiatives. This guide explores critical portfolio metrics—from business value realized to delivery predictability—with practical examples and implementation strategies to enhance decision-making, team alignment, and organizational outcomes.
When your organization’s delivery costs keep climbing, it’s rarely just a budget management issue—it’s a systemic problem that silently erodes performance. From excessive coordination overhead to the paralyzing expense of changing direction, high delivery costs can cripple your ability to adapt. In this article, we explore how the pursuit of adaptability paradoxically increases costs, why seemingly busy teams produce diminishing returns, and the strategic roots of this pervasive challenge facing modern organizations.
In today’s continuous delivery environment, the inability to clearly see real-time progress represents more than a minor oversight—it’s a critical vulnerability that threatens strategic goals. When forward momentum becomes invisible, leaders struggle to confirm whether initiatives remain on track, teams lose alignment, and organizations risk missing strategic targets. This article explores how complexity, silos, inefficient communication channels, and cultural obstacles create dangerous blind spots, and why addressing visibility is crucial for maintaining quality, morale, and financial health in modern delivery ecosystems.
In modern organizations, ‘benefit blindness’ occurs when employees and leaders fail to see how their efforts connect to tangible outcomes. This phenomenon, likened to ‘flying blind,’ diminishes motivation, misallocates resources, and weakens strategic alignment. Discover the root causes and significant impacts of this systemic problem.